
Different Learning Styles – How to Design Learning to Accommodate our Learners?
People learn in different ways. We all have our individual preference for the ways in which we learn. In this post, we will explore different models to categorize learners into different learning styles. We will also explain how to design learning to accommodate our learners.
Understanding the different learning styles will influence the design and assessment strategies. That’s why it is important to know some models so we can cater for a wider group of learners.
What are learning styles?
There are numerous theories which discuss different learning styles. In the past few decades, educational theorists have expanded the work of psychologists in the area of individual learner differences.
As a result, a number of theories have emerged about how people can be classified into different groups based on how they learn more effectively and their preferences.
Generally most theorists describe learning styles as different aspects of the ways that people learn, process information and respond to environmental stimuli in different dimensions.
Some theorists and researchers have identified the following definitions of learning styles:
- The way that individuals attend to and integrate complex new information determines which style categorizes a learner (Dunn, 1978). Additionally, personal choice and preference play a role in what style one chooses for learning.
- Dunn (1978) indicated that learning styles are approaches to learning and studying.
- Keefe (1982) defined learning styles as characteristic cognitive, affective and psychological behaviors that serve as relatively stable indicators of how learners perceive, interact with or respond to the learning environment.
- Dunn and Perrin (1994) described learning styles as “the way in which each learner begins to concentrate on, process and retain new and difficult information. That interaction occurs differently for each individual” (p. 2).
- Gilbert and Han (1999) and Gilbert (2000) confirmed that learning preferences facilitate the way individuals learn when the learning environment considers the various learning styles of students, thereby impacting the comprehension of materials presented.
- Felder and Spurlin (2005) described learning styles as “characteristic strengths and preferences in the ways they take in and process information” (p. 1). Felder (2005) indicated that learning styles are often reflected in “different academic strengths, weaknesses, skills, and interests” (p. 3). Learning styles are often influenced by heredity, upbringing and current environmental demands. Individuals have a tendency to both perceive and process information differently.
Learning styles are not unique and fixed for each individual. They fluctuate within subject or lesson and each person will have a variety of learning styles and preferences.
There are many frameworks or models to classify learners into specific learning styles. In this article we will explore the following models:
- Multiple Intelligence Theory.
- Split Brain Theory (left-brain, right-brain).
- Global and Analytical Learner Model.
Multiple Intelligence Theory
The Theory of Multiple Intelligence was developed in 1983 by Howard Earl Gardner and it was first published in his book Frames Of Mind: The Theory Of Multiple Intelligence.
Frames Of Mind: The Theory Of Multiple Intelligence.
Its basis opposes the idea of a single dominant type of intelligence, and instead acknowledges the existence of multiple intelligence, that compose a unique blend in each individual.
The Multiple Intelligence Theory indicates that each type of human intelligence represents a different way of processing information. The different intelligence are:
- Verbal-linguistic: refers to an individual’s ability to analyse information and produce work that involves oral and written language, such as speeches, books and memos.
- Logical-mathematical: describes the ability to develop equations and proofs, make calculations and solve abstract problems.
- Visual-spatial: allows people to comprehend maps and other types of graphical information.
- Musical: enables individuals to produce and make meaning of different types of sound.
- Naturalistic: refers to the ability to identify and distinguish among different types of plants, animals and weather formations found in the natural world.
- Bodily-Kinaesthetic: entails using one’s own body to create products or solve problems.
- Interpersonal: reflects an ability to recognize and understand other people’s moods, desires, motivations and intentions.
- Intrapersonal: refers to people’s ability to recognize and assess those same characteristics within themselves.
Design Strategies for Multiple Intelligence Theory in eLearning
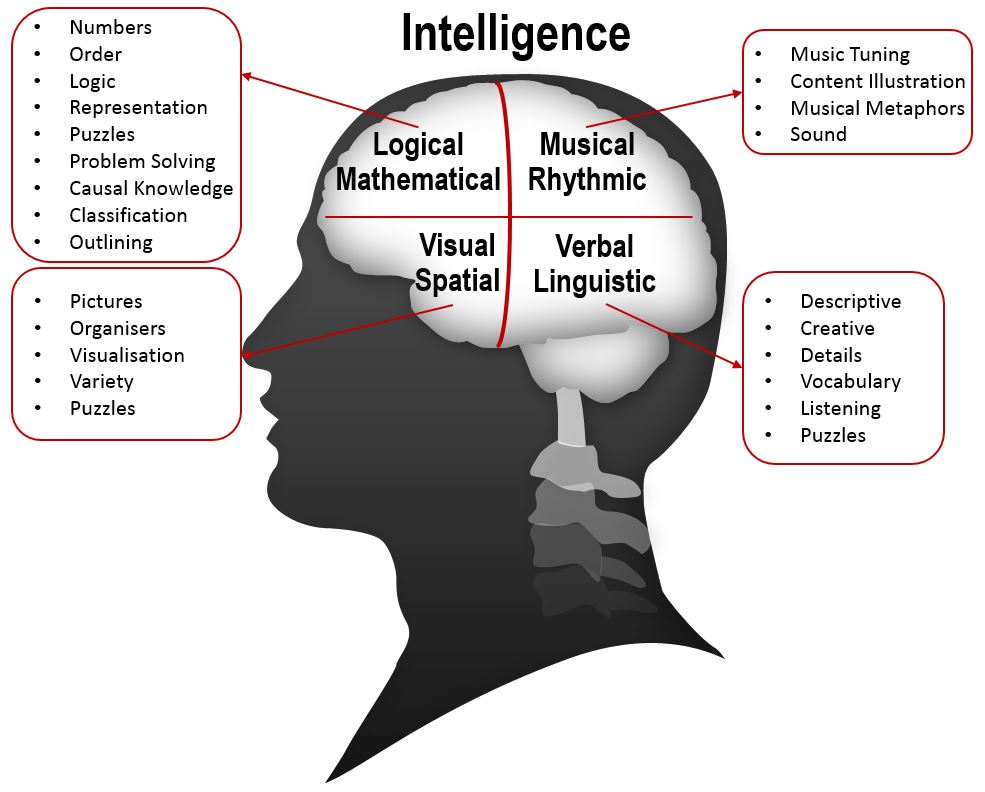
The following picture shows the different multiple intelligence and some strategies that can be used to implement them.

Another set of activities suitable for the different multiple intelligence is shown below:

Source: http://www.mmiweb.org.uk/downloads/mi.html
And finally, more design strategies are listed in the following table:
| Intelligence | Design Strategies |
| Verbal-linguistic | Scenarios, discussions on forums, links to additional information concerning the subject matter. |
| Logical-mathematical | Graphics, charts, tables, critical thinking branching scenarios, where learners are required to find the answer using a series of clues. |
| Visual-spatial | Use of color, images, illustrations, graphics, games and multimedia that are visually appealing. |
| Musical | Music and sound, such as multimedia presentations with audio, narrations, podcasts, voice recordings. |
| Bodily-Kinaesthetic | Include virtual environments and activities that require physical involvement, such as drag and drop interactions, eLearning games, and simulations. Include several interactive methods and techniques to encourage kinaesthetic learners feel, touch, move, and manipulate objects. Here some VR/AR experiences might be a good option too. |
| Interpersonal | Forums and chats to encourage the exchange of ideas and social learning. Prompt learners to share their own experiences, views and ask them to make decisions while putting themselves in someone else’s shoes in scenario-based activities. |
| Intrapersonal | Scenarios that offer real world benefits is ideal for them, as they become more engaged when introspecting and reflecting. Moreover, don’t hesitate providing your intrapersonal learners with material for further private study, as it will help them gain a sense of what they want to achieve or what are the mistakes to avoid in their personal or professional lives. |
Split Brain Theory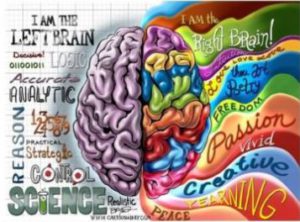
In the 1960s, neuroscientist Roger W. Sperry discovered that by cutting the corpus callosum, a large bundle of fibres that connects the right and left hemispheres of the brain, he could reduce seizures in patients with epilepsy. The results of these experiments also revealed that the 2 sides of the brain performed different tasks.
Anatomically, the brain is divided into 2 hemispheres; the left and right. Studies have indicated that the 2 hemispheres have different functions and characteristics.
Based on these studies and the lateralization of the brain function, we have the theory of left-brain or right-brain. According to the theory of left-brain or right-brain dominance, each side of the brain controls different types of thinking. Additionally, people are said to prefer one type of thinking over the other.
According to the left-brain, right-brain dominance theory, the right side of the brain is best at expressive and creative tasks. Some of the abilities popularly associated with the right side of the brain include:
- Recognizing faces.
- Expressing emotions.
- Music.
- Reading emotions.
- Color.
- Imagination.
- Intuition.
- Creativity.
The left-side of the brain is considered to be adept at tasks that involve logic, language, and analytical thinking. The left-brain is described as being better at:
- Language.
- Logic.
- Critical thinking.
- Numbers.
- Reasoning.
Design Strategies for Split Brain Theory in eLearning
For learners with more tendency to the left hemisphere, some activities would include presenting information in numerical tables, with facts, figures, statistics, showing content in a logical order and sequences.
The assessments would require learners to organize facts, accurate responses involving recall of information and solutions of specific problems.
For right hemisphere learners, I would include activities that involve presenting images, asking for emotions, opinions and feelings in regards to the information presented rather than factual responses. I would include scenarios or case studies to let learners imagine possible responses and suggest different solutions, predict outcomes and apply solutions to hypothetical problems.
Every eLearning module would include activities for both styles.
Global and Analytical Learner Model
In the Global Learner Model, the learner takes in information holistically. Begins with understanding concepts first, with mastery of details to follow. On the other hand, in the Analytical Learner Model, the learner takes in information sequentially, step-by step, preferring to learn a series of facts that lead toward an understanding of a larger concept.
Global learners need to see the big picture first and know the end result before beginning. While the analytical learners like to learn one piece at a time; they enjoy a clear sequence that starts at the beginning and moves to the end one step at a time.
In my workplace, I would design and adapt the eLearning modules to cater both styles as follows:
- Include the learning objectives of the training.
- Present a list of what learners will achieve at the end of the course.
- Start with the basic concepts, one step at a time and then build up the complexity of the content as the learner progresses.
Identify your Own Learning Style
There are different tests and tools you can use to determine your learning style and preferences.
The DISC assessment is an inventory model of learning styles which is composed of four quadrants classified by behavior. DISC is an acronym for Dominance, Influence, Steadiness, and Conscientiousness.
Other tool I have used is called “HBDI – Herrmann Brain Dominance Instrument”. This instrument was developed by Ned Herrmann after investigating split-brain theory and using technologies such as Electroencephalography (EEG), Positron Emission Tomography (PET) and Magnetic Resonance Imaging (MRI). HBDI allows you to become aware of your thinking preferences in order to use them better in your professional and personal life.
The HBDI test consists of 120 questions and the results and then categorized in four quadrants.


Other test you can do completely free is in this link https://personalitymax.com/
They will also provide with a snapshot on your preferences and your learning styles.


Designing eLearning for All Learning Styles
I believe it is possible in a post-modern world to provide instruction that will serve a wide range of learners without getting too tangled in the maze of learning style theories.
Basically, exposure to different instructional approaches is important. Incorporating a variety of teaching and assessment methods, being aware of cultural differences and providing students with opportunities to reflect on thinking will improve learning outcomes.
The type of instruction needed depends significantly on the discipline, the context and the content of what is being taught (Paschler, McDaniel, Rohrer, & Bjork 2008). A thorough analysis of these elements ensures that instruction will be aligned with expected outcomes.
A geometry course, for example, will likely have a much different presentation than will a writing course. Independently of the course, I would provide learners with plenty of opportunities to engage in critical thinking as a way to deconstruct and reconstruct the desired content in any discipline.
When a learner is exposed to different media in an instructional module, they will develop multiple schemas while working together for mastery of content.
Mayer’s Cognitive Theory of Multimedia Learning proposes that the best instruction includes information presented both visually and aurally, without redundancy or overload. We discussed these multimedia strategies in the post “Richard Mayer on Multimedia Learning”.
For digital environments, designers need to have a sundry toolbox to make the instruction clear and adaptable.

Approaches and Implementation Techniques for Developing Multiple Intelligence Content
Verbal / Linguistic Intelligence |
|
| Descriptive Writing | Summaries, procedures, problem solving, narrative. |
| Creative Writing | Stories, history, wordplay, metaphors, myths, legends, plays, prose, poetry. |
| Details | Facts, names, places, trivia. |
| Vocabulary Focus | Keywords, origins and definitions of terms. |
| Listening | Verbal recordings. |
| Puzzles | Word puzzles and games. |
Logical / Mathematical Intelligence |
|
| Numbers | Mental arithmetic, calculations, measurements. |
| Mathematical Order | Steps, procedures, sequences, patterns. |
| Logic | Scientific, deductive, syllogisms, Venn diagrams, inductive, analogies. |
| Visual Representation | Graphs, charts, pie charts, grids, matrices. |
| Maths Representation | Codes, symbols, formulas. |
| Puzzles | Logic puzzles and games. |
| Problem Solving | Estimations, predictions, exploration. |
| Causal Knowledge | Questioning, cause and effect, logical meanings and relationships. |
| Classification | Compare/contrast, attribute identification, categorizations, ranking. |
| Outlining | Logical explanations, logical thought maps, sequence charts. |
Visual / Spatial Intelligence |
|
| Pictures | Drawings, maps, diagrams, artwork, photography, videos, slides, movies. |
| Visual Organizers | Flowcharts, visual outlines, concepts maps, mind maps. |
| Internal Visualization | Visual thinking exercises, imaginations, guided imagery, visual memory. |
| Visual Variety | Patterns, designs, color, texture, geometric designs, unusual positions. |
| Puzzles | Visual puzzles, mazes, games. |
Musical / Rhythmic Intelligence |
|
| Music Tuning | Background music, mood setting, sound breaks and jingles. |
| Content Illustration | Songs, raps, chants. |
| Musical Metaphor | Tones, notes, rhythms, clapping. |
| Sounds | Instrumental, environmental, nature. |
The Challenge for Instructional Designers
An instructional designer would find challenging to determine which system of learning-style classification would be most appropriate for a particular project. There are so many style inventories that, in their own right, seem logical and suitable for dividing people into groups for instructional planning purposes.
However, no one model is going to fit or match the potential range of learners.
Instruction that is engaging, flexible and relevant to the intended audience, and that is presented in ways that encompass varied avenues of access is likely to meet the needs of diverse learners, no matter what their current or preferred style may be (Paschler, McDaniel, Rohrer, & Bjork 2008).
A person’s thinking about and attention to their individual learning preferences may be useful in developing a metacognitive awareness of how best to approach a particular learning goal, which is highly dependent on the discipline, the content and the context of the task.
But it is not useful to lock oneself into a learning style that limits participation in engaging learning experiences offered through a variety of well-designed instructional strategies.
It is important not to label a learner within a preferred style but to challenge them to try using different learning materials. Also encourage your students to use a range of activities in an eLearning environment to cater for all styles.
Learners stereotyped as having one particular learning style may find themselves locked into one kind of learning experience, discouraging experimentation with other learning approaches.
Rather, all learners will likely benefit, over time, by being exposed to and using a varied toolbox of cognitive strategies to access content knowledge.
In Summary
To face these challenges of multiple intelligence and learning styles I would suggest two practices.
Firstly, I would focus on promoting among the learners metacognition strategies for learning effectively such as elaboration, comprehension monitoring, and mnemonics.
And secondly, I support the idea of designing learning experiences that incorporate a variety of methods to cater for all learning styles and that promote the development of multiple intelligence.
When designing instructional systems I would keep in mind the use of technologies to support different learning strengths. For example, there is in the market software to stimulate verbal/linguistic intelligence, or calculus activities to develop logical/mathematical intelligence, logic puzzles and games, or drawings and artwork to promote visual/special intelligence.
Technology can be used in the classroom along with traditional activities to help students develop their intelligence (Bennett & Tipton, 1996).

In the online environment, on the other hand, as internet technologies become more user-friendly and accessible, instructional designers can create learning experiences that incorporate activities that appeal to the different intelligence and thus increasing learner responsiveness (Osciak & Milheim, 2001).
Each strategy in the learning experience will benefit learners in a different way, and learners will get out more or less from a particular strategy, but the important point to keep in mind is to include a variety of instructional methods and encouraging learners to use effective learning habits.
The key message at the end is “to offer variety and learners will be happy” 😀
I hope you liked this post. Feel free to leave your comments below and tell me what are your preferences and learning styles?
See you next time,
Thais 🙂
References
Bennett, C.K. & Tipton, P.E. (1996). Using technology to develop multiple intelligence in the classroom. In B. Robin et al. (Eds.), Proceedings of Society for Information Technology & Teacher Education International Conference 1996 (pp. 976-978). Chesapeake, VA: Association for the Advancement of Computing in Education (AACE).
Dunn, K. & Dunn, R. (1978). Teaching students through their individual learning styles: A practical approach. Reston, VA: Reston Publishing.
Dunn, R., Dunn, K., & Perrin, J. (1994). Teaching young children through their individual learning styles. Boston, MA: Allyn & Bacon, Inc.
Felder, R. M., & Spurlin, J. E. (2005). Applications, reliability and validity of the Index of Learning Styles. International Journal of Engineering Education, 21(1), 103-112.
Gilbert, J. E., & Han, C. Y. (1999). Adapting instruction in search of a significant difference. Journal of Network and Computing Applications, 22(3), 149-160.
Gilbert, J. E. (2000). Case based reasoning applied to instruction method selection for intelligent tutoring systems. Workshop Proceedings of ITS’ 2000: Fifth International Conference on Intelligent Tutoring Systems, Montreal, CA.11-15.
Keefe, J. (1982). Student learning styles and brain behavior: Programs, instrumentation, research. Reston, VA: National Association of Secondary School Principals.
Kelly, D. Brendan, T. (n.d.). A Framework for using multiple intelligence in an ITS.
Khalsa, G. (2013). Should Instructional Designers Accommodate Learning Styles?. In R. McBride & M. Searson (Eds.), Proceedings of Society for Information Technology & Teacher Education International Conference 2013 (pp. 1350-1355). Chesapeake, VA: Association for the Advancement of Computing in Education (AACE).
Osciak, S. & Milheim, W. D. (2001). Multiple intelligence and the design of web-based instruction. International Journal of Instructional Media (pp. 355-361). Retrieved from http://www.acdowd-designs.com/sfsu_860_11/MI and design of web-based instruction.pdf
Pappas, C. (2015). Multiple Intelligence in eLearning: The Theory and its impact. [Web]. Retrieved from https://elearningindustry.com/multiple-intelligence-in-elearning-the-theory-and-its-impact
Pashler, H., McDaniel, M., Rohrer, D., & Bjork, R. (2008). Learning styles: Concepts and evidence. Psychological Sciences in the Public Interest, 9(3), 103-119.
15 Responses
I always joke with my mom about being a right brain and her DEFINITELY being a left brain. I’m artistic, semi-dramatic (lol), more expressive and social. My mom is an analytical thinker, she does numbers for a living and is a bit of an introvert. I enjoyed learning more about my mom and I in your post as well as seeing in more detail exactly what kind of learner I am. I’ve always learned better by being shown rather than reading it in a book, etc. I’d also never heard of the naturalistic/spiritual grouping. I fit into that and the visual/spatial category for sure. Thanks for the great info!
Hi Jennifer, I’m glad you discovered other intelligence styles here. It is good to know out styles so we know more how we are happier to consume training and content in general.
I’ve always leaned more toward kinesthetic learning and my least favorite learning method is auditory. If someone tries to teach me something just by talking, I might forget 99.9% of what they just said unless the subject matter is interesting to me. If I’m moving, role playing, using any kind of physical action, I’m so much better at gripping something. Even at my day job, they try to onboard us with auditory and visual learning and it couldn’t have been more confusing. However, once I gained hands-on experience, I was fine and picked up faster than most.
Hi Todd, that is a such a cool way to learn. Hands on training and practicing knowledge is so valuable for learning. Lots of technical careers are best learned this way. You might need some more technological tools like VR/AR experiences to have a more engaging learning experience for your preferences. Thanks so much for reading and commenting.
I love this as it really gives insight to just how man different ways there are to learn! I myself learn best I feel by visuals but after reading this I may have to give a few others a try as well!
Hi Keenan,
I’m happy to see that you might give other styles a try. That’s so important! We need to challenge ourselves all the time and also we will have more opportunities to discover other ways to consume content and education. Thanks for reading and commenting 🙂
This is really quite interesting. I never realized that there were so many ways people learn and we each have our own particular way. I went over to check out the test because I thought it would be good to find out how I learn. I’ll have to try it later when I have more time, because it says it takes 25 minutes. So I will be doing that. Thanks so much for the information.
Hi Lynn, I’m glad you found something useful in the post. The test will also tell you which careers are more aligned with your preferences. That’s such a good resource for students in high school when they don’t know what to do next.
That is so cool! Human body is so magical! Thank you for sharing this! I like to see a picture that makes me simple to understand this, great article!
Thanks so much 😀 I’m glad you like it.
Thai,
Really enjoyed this post and the explanation of all the learning types.
I especially appreciated your conclusion about the importance of variety in learning for every type of learner to stretch each individuals ability to adapt to different learning styles.
I personally struggled with traditional classroom learning because of the difficulty I experienced focusing in a large classroom setting. but I excelled at online learning which was much more personally engaging and allowed me to focus. I think technology and e-learning have opened the doors to learning for many people that once fell through the cracks of the traditional learning models.
Great information!
Hi Joe, I’m the same! I struggled so much in uni with the traditional lessons. In the online environment I feel more comfortable.
Yep, for me, it’s logical. I’m very conceptual in nature and HATE memorizing stuff. It forces me to do so much work and wastes my energy. But with concepts, I can understand the know how and let everything else fall into place. Great post and very educational!
Memorising is a waste of time, you are right. And even more now where information is so easy to access. The important piece of knowing how to apply concepts 🙂
viagra canada https://telegra.ph/Kak-vybrat-gazovyj-kotel-dlya-chastnogo-doma-02-14
Helpful posts. Thanks a lot.